Ejemplos de Microservicios con Java

- ¿Tu compu tiene Microsoft ?
- ¿Office o Windows?
- Microsoft XP .
La gente pensaba así por default.
Y algo así lo estoy viendo ahora con esta nueva tecnología llamada Microservicios: Solo se hace con SpringBoot.
Pues bien, en este post mostraré tres (03) frameworks en Java que permiten hacer Microservicios, sin usar SpringBoot.
No niego que SpringBoot tenga muchas bondades, solo quiero mostrar que también con otros frameworks se pueden hacer lo mismo.
Dicho esto, comencemos.
Spark
No confundir con Apache Spark.
Si has visto cómo hacer un servicio REST con Node JS, pues es muy similar. No necesitamos de una aplicación o módulo web. Es una aplicación para ejecutarse desde la línea de comandos, por tanto, no necesita de un contenedor web, ya que viene el jetty incluido en las dependencias.
Considerando la dependencia en Maven:
Si has visto cómo hacer un servicio REST con Node JS, pues es muy similar. No necesitamos de una aplicación o módulo web. Es una aplicación para ejecutarse desde la línea de comandos, por tanto, no necesita de un contenedor web, ya que viene el jetty incluido en las dependencias.
Considerando la dependencia en Maven:
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.7.1</version>
</dependency>
La clase Main es como sigue:
import static spark.Spark.*;
public class Main {
public static void main(String[] args) {
get("/info", (req, res) -> "Este es un ejemplo de Spark");
}
}
Y Listo, lo ejecutamos:

Por omisión, lo estará ejecutando en el puerto 4567. Ahora bien, problemos llamando a ese host, y a la ruta 18 de java, donde dice
get("/info"...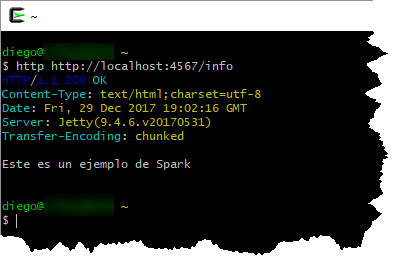
Fácil ¿cierto?
Ahora bien.. ¿si quiero hacer un post?
Para ello, asumiremos una clase
Persona y su repositorio PersonaRepository para manipular el listado.Hecho esto, agreguemos estas líneas:
post("/persona", (req, res) -> {
String nombre = req.queryParams("nombre"); //recibe el parámetro nombre
String edad = req.queryParamOrDefault("edad", "0"); //recibe el parámetro edad. Si no está, lo pone en cero (0)
Persona persona = PersonaRepository.addPersona(nombre, edad); //lo registra en el listado
res.type("application/json"); //prepara el tipo a responder...
return new Gson().toJson(persona); //.. y devuelve el objeto creado
});
Y listo. Ahora lo probamos. Usaremos httpie (que considero más simple de usar.. además que las respuestas se ven más legibles)

¿No conoces el httpie y quieres usar el cURL? Bueno, también funciona:

¿Solo conoces Postman? Bueno, tranquilo, también funciona

Ahora ¿quieres jalar un registro vía parámetros en el URL? Pues bien, aquí agregamos estas líneas.
get("/persona/:id", (req, res) -> PersonaRepository.getById(Integer.parseInt(req.params("id"))), json());
¿De dónde apareció ese método
json()? Es de otra clase:
package com.apuntesdejava.spark;
import com.google.gson.Gson;
import spark.ResponseTransformer;
public class JsonUtil {
public static <T> String toJson(T e) {
return new Gson().toJson(e);
}
public static ResponseTransformer json() {
return JsonUtil::toJson;
}
}
Y agregamos el import a la clase Main
import static spark.Spark.*; import static com.apuntesdejava.spark.JsonUtil.*;
Como habrás notado, la gran fortaleza de Spark es que utiliza las sintaxis funcional de Java 8.
El código fuente completo para este ejemplo se encuentra aquí: https://bitbucket.org/apuntesdejava/microservicios-ejemplos/src/master/spark/
¿Cómo manejamos la persistencia / modelo / base de datos? Pues, Spark solo es un framework web, así que puedes usar el manejador de base de datos que quieras: JDBC puro, MyBatis, Spring (je), o todo lo que quieras.
Jersey
Justo en su página web lo primero que explica es cómo crear un proyecto Jersey desde un Archetype.
En la misma página también explica cómo funciona en un contenedor web como GlassFish (que ya viene incluido) o en uno que no tenga (como el Tomcat / jetty.. etc)
(Para este ejemplo, utilicé los pasos indicados, pero le hice unas modificaciones para ajustarse a este post, pero no son graves ni cruciales.)
A diferencia del Spark, Jersey utiliza la sintaxis propia de Java EE. Por ello, podemos crear un servicio de la manera común:
Jersey tiene tres clases para ejecutar el servidor.
El que está arriba es usando
GrizzlyHttpServerFactory.
La otra clase es usando
com.sun.net.httpserver.HttpServer que apareció en Java SE 6. Aquí está el ejemplo:
La tercera clase es
org.glassfish.jersey.simple.SimpleServer, aquí el ejemplo:
En cualquiera de los casos, carga todos las clases que están en el paquete
com.apuntesdejava.jersey, por esta línea
//...
final ResourceConfig rc = new ResourceConfig().packages("com.apuntesdejava.jersey");
//..
Ahora bien, probemos la ejecución. Usaremos los mismos parámetros, pero consideremos que es otro puerto y otro URI:
Ejecutamos el servicio desde la línea de comandos:

Ahora, llamemos a los servicios:

Al igual que Spark, el manejo de la persistencia queda de nuestro lado: podemos usar el framework que querramos.
El proyecto completo está aquí: https://bitbucket.org/apuntesdejava/microservicios-ejemplos/src/master/jersey-standalone/
Payara Micro

Spark te da su propia manera de manejar las peticiones, aunque no es estándar. Jersey, así como Spark, no te da un manejador de persistencia, a menos que lo hagamos nosotros.
En cambio, Payara Micro está basado en GlassFish, compatible con Eclipse MicroProfile, pesa menos de 70MB, permite clustering automático mediante Hazelcast, usa JCache, y todas las características que tiene Java EE (incluyendo JPA, Datasource, JAAS, JavaMail, etc)... además de ejecutar nuestro .war. Ya que todas las bibliotecas ya está en el Payara Micro, nuestro .war solo pesará lo necesario.
Para poder desarrollar para Payara Micro es, básicamente, hacer una aplicación Java Web, como cualquiera... y además de establecer la clase de configuración para RESTful.
Y nuestro servicio sería como esto:
Para fines de desarrollo, lo podemos ejecutar tranquilamente en nuestro Payara local usando nuestro IDE. Y si está ya todo listo, podemos ponerlo en producción de tres maneras: usando una aplicación Java de consola, usando
payara-micro.java desde la línea de comando, o empaquetándolo dentro de un solo .jar.
Las dos primeras maneras ya lo publiqué en un post anterior: Payara Micro. En esta vez (y como está en este proyecto ejemplo) usaremos Uber-JAR para generar un solo .jar de nuestra aplicación junto con Payara Micro.
Crearemos nuestro .war desde Maven.
mvn clean package
Y lo ejecutamos desde la línea lo siguiente
java -jar c:\opt\payara-micro-4.1.2.174.jar --port 8100 --deploy target\payara-service-1.0.war --outputuberjar mi-servicio.jar
Y ya tenemos nuestro servicio en
mi-servicio.jarPero, para hacerlo más profesional, generaremos el Jar "gordo" desde Maven. Cada vez que empaquetemos el proyecto con un perfil en especial, tendremos esta aplicación lista.
Esta sería la configuración del pom.xml
<profile>
<!-- perfil de distribucion -->
<id>dist</id>
<dependencies>
<!-- consideramos el payara-micro -->
<dependency>
<groupId>fish.payara.extras</groupId>
<artifactId>payara-micro</artifactId>
<version>${payara.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<finalName>payara-service</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.0.2</version>
<executions>
<execution>
<!-- Copiamos el .jar de payara a la carpeta target -->
<id>copy-payara-micro</id>
<goals>
<goal>copy</goal>
</goals>
<configuration>
<outputDirectory>target</outputDirectory>
<stripVersion>true</stripVersion>
<silent>true</silent>
<artifactItems>
<artifactItem>
<groupId>fish.payara.extras</groupId>
<artifactId>payara-micro</artifactId>
<type>jar</type>
</artifactItem>
</artifactItems>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<!-- ejecutaremos en la linea de comando -->
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<dependencies>
<dependency>
<groupId>fish.payara.extras</groupId>
<artifactId>payara-micro</artifactId>
<version>${payara.version}</version>
</dependency>
</dependencies>
<executions>
<!-- crearemos nuestro payara uber jar -->
<execution>
<id>payara-uber-jar</id>
<phase>package</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<executable>java</executable>
<!-- esto son todos los parámetros para crear el jar -->
<arguments>
<argument>-jar</argument>
<argument>target/payara-micro.jar</argument>
<argument>--port</argument>
<argument>9595</argument>
<argument>--logo</argument>
<argument>--nocluster</argument>
<argument>--deploy</argument>
<argument>${basedir}/target/${project.build.finalName}.war</argument>
<argument>--outputuberjar</argument>
<argument>${basedir}/target/${project.build.finalName}.jar</argument>
<argument>--logtofile</argument>
<argument>${basedir}/payaramicro.log</argument>
</arguments>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>
Ahora, cuando ejecutemos la siguiente línea de comando:
mvn clean package -Pdist
tendremos nuestro paquete:

Ahora, nos toca simplemente, ejecutar el .jar desde la línea de comandos:
java -jar target\payara-service.jar

Y listo, probemos las peticiones:

Proyecto completo
El proyecto completo está en Git y se puede obtener en la siguiente página:
Es un proyecto base y los tres proyectos usados en este post son subproyectos.
En el
pom.xml principal le puse una configuración adicional de tal manera que cada vez que se empaquete cada proyecto se copie todas las bibliotecas adicionales (jar) a la subcarpeta target/lib de tal manera que se pueda distribuir la aplicación, tal como está explicado en un anterior post: Maven: Crear app .jar ejecutable con bibliotecas dependientes.

تعليقات
إرسال تعليق
Si quieres hacer una pregunta más específica, hazla en los foros que tenemos habilitados en Google Groups
Ah! solo se permiten comentarios de usuarios registrados. Si tienes OpenID, bienvenido! Puedes obtener su OpenID, aquí: http://openid.net/